
#33 - High Availability Patterns Explained
How Your Favorite Restaurant Can Teach You About Cloud Infrastructure


Intro
I visited a favorite restaurant a few weeks ago. According to all indications, it should have been open, but when I arrived, it was closed for maintenance. While I did find another place to eat, I was disappointed I couldn’t eat where I originally wanted. The next time, I hesitated to go there, feeling they were unreliable and might be closed again.
The same thing happens with software products. Unresponsive sites, ever-loading processes, and app crashes all point to an unstable product. The technical term is downtime or outage, meaning the service is unavailable and can’t accept traffic. Facebook had a well-known outage on March 13th, costing an estimated $90M. A five-hour outage at Delta Air Lines cost around $150M. Research from 2016 shows an average cost of $9K per minute of downtime for a company. Long story short, outages are bad for your business, especially for cash-strapped startups.
To deal with downtimes, high availability patterns ensure continuous operational access with minimal downtime. Let’s examine a few of these patterns using the restaurant example.
High Availability Patterns
Load Balancer
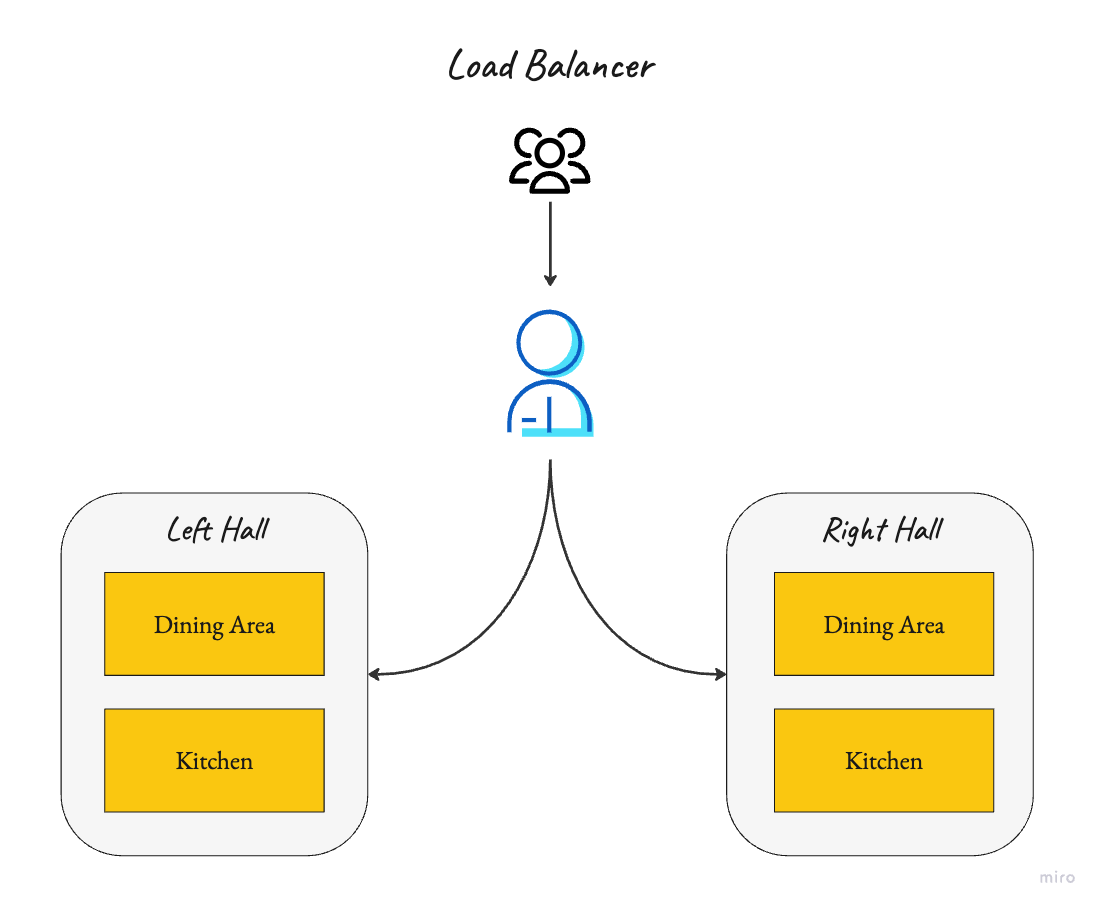
The load balancer (the host) directs traffic (guests) to different sections of the restaurant (Left Hall and Right Hall), each with its own dining area and kitchen, to ensure no single section is overwhelmed.
This method is helpful in efficiently distributing workload and preventing any single server from becoming a bottleneck.
Auto Scaling
If the restaurant gets busier, additional halls (and their respective kitchens) will open to accommodate the increased number of guests. This ensures the restaurant can handle varying loads by dynamically adjusting the available resources, similar to how auto-scaling automatically adjusts the number of running instances based on current demand.
This method is helpful to maintain performance during peak times and optimize resource usage.
Circuit Breaker

The load balancer (the host) redirects traffic (guests) away from a section (Left Hall) that is temporarily closed (indicated by the barrier and red cross) to another section (Right Hall) that is still operational, preventing overload and allowing the closed section to recover.
This method is helpful to maintain service continuity and prevent system failures.
Clustering
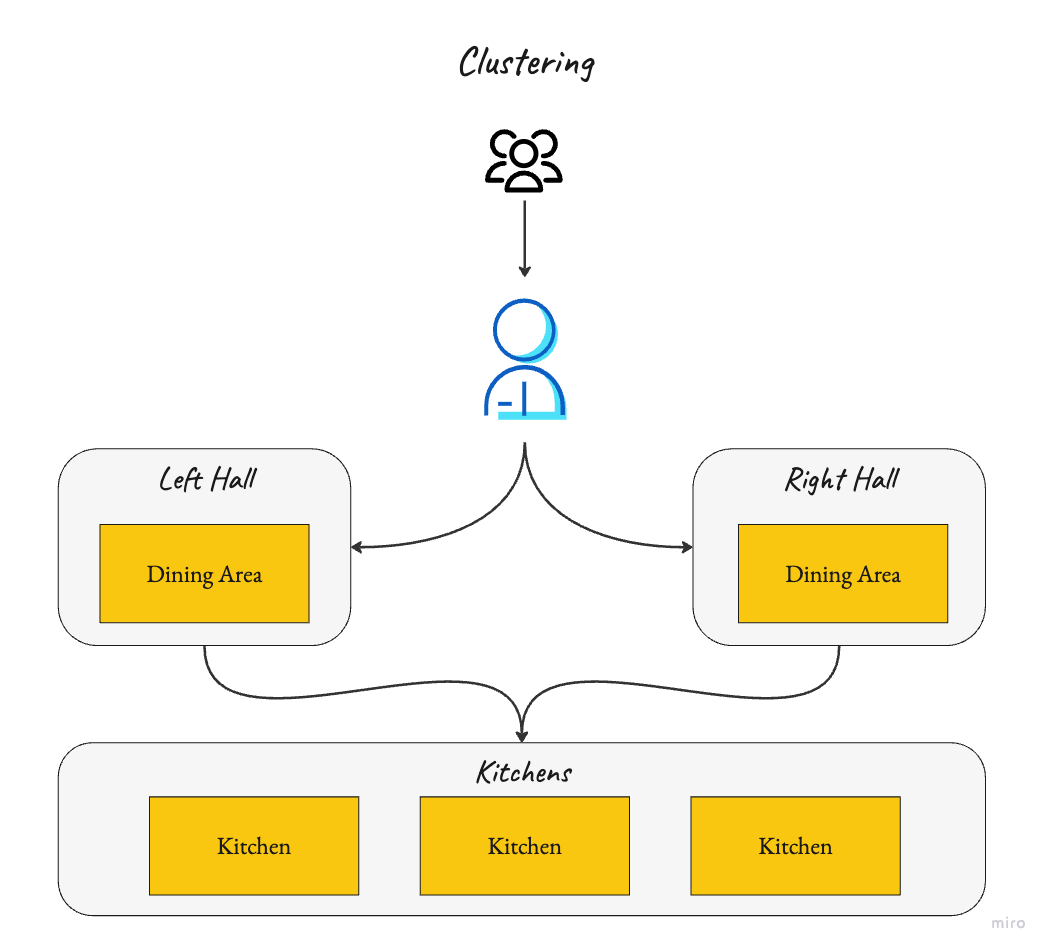
With clustering, multiple kitchens work together to prepare food for different dining areas (Left Hall and Right Hall). This ensures that if one kitchen has an issue, others can continue to provide service, thereby maintaining high availability and scalability.
This method is helpful to ensure fault tolerance and improve system reliability.
Sharding

Sharding is a more creative solution. Different kitchens specialize in specific types of dishes (openings, main dishes, desserts) and serve multiple dining areas (Left Hall and Right Hall). This division of labor distributes the workload efficiently, similar to how sharding splits a database into smaller, more manageable pieces, each handling a portion of the overall demand.
This method is helpful to optimize performance and manage large-scale systems effectively.
Replica Set

The restaurant has a main chef responsible for preparing dishes and a backup chef ready to take over if the main chef is unavailable. This ensures service continues smoothly without disruptions, similar to how replica sets maintain multiple copies of data across different servers for redundancy and high availability.
This method is helpful to ensure continuous service and prevent data loss.
Summary
Outages hurt customer experience and overall business performance; high availability patterns help mitigate this risk. Even a simple restaurant can learn something from cloud infrastructure and coding practices.