
#36 - Online vs Offline Approaches
Balancing Fresh Data and System Resilience


Intro
Imagine a Product Manager working on improving the registration flow of a product. Recently, analysts discovered fraudulent traffic skewing the usage data and created a model that assigns a fraud score per domain. For simplicity, let’s assume we need to block registrations from domains with a fraud score over 100.
Our excited Product Manager writes this User Story:
As a Product Manager,
I want to block fraudluent traffic
So that only legitimate users can create accounts.
She provides two acceptance criteria:
Given user A from domain X
And domain X has a fraud score of 35
When user A tries to register
Then he will succeed.Given user B from domain Y
And domain Y has a fraud score of 105
When user B tries to register
Then he will fail
And he will see a relevant error message.
Let’s explore two alternatives to implement this requirement: the “online” and the “offline” approaches (previously discussed as Sync and Async).
Online Approach
The engineers suggest this approach:
In this approach, each registration attempt involves calling the Fraud service to get the domain fraud score. Here are the main pros and cons:
Pros
Fresh Data: Each attempt uses the most up-to-date available data for the domain.
Cheap: This approach is relatively inexpensive to develop, relying mainly on existing data from the Fraud service.
Cons
Prone to Errors: Changes in the Fraud domain can directly impact the registration flow. A simple API contract change can disrupt the entire registration process.
Availability Issues: The registration flow is dependent on the Fraud service. The team must handle cases where the Fraud service is unavailable or slow to respond.
Offline Approach
The team brainstorms and comes up with this suggestion:
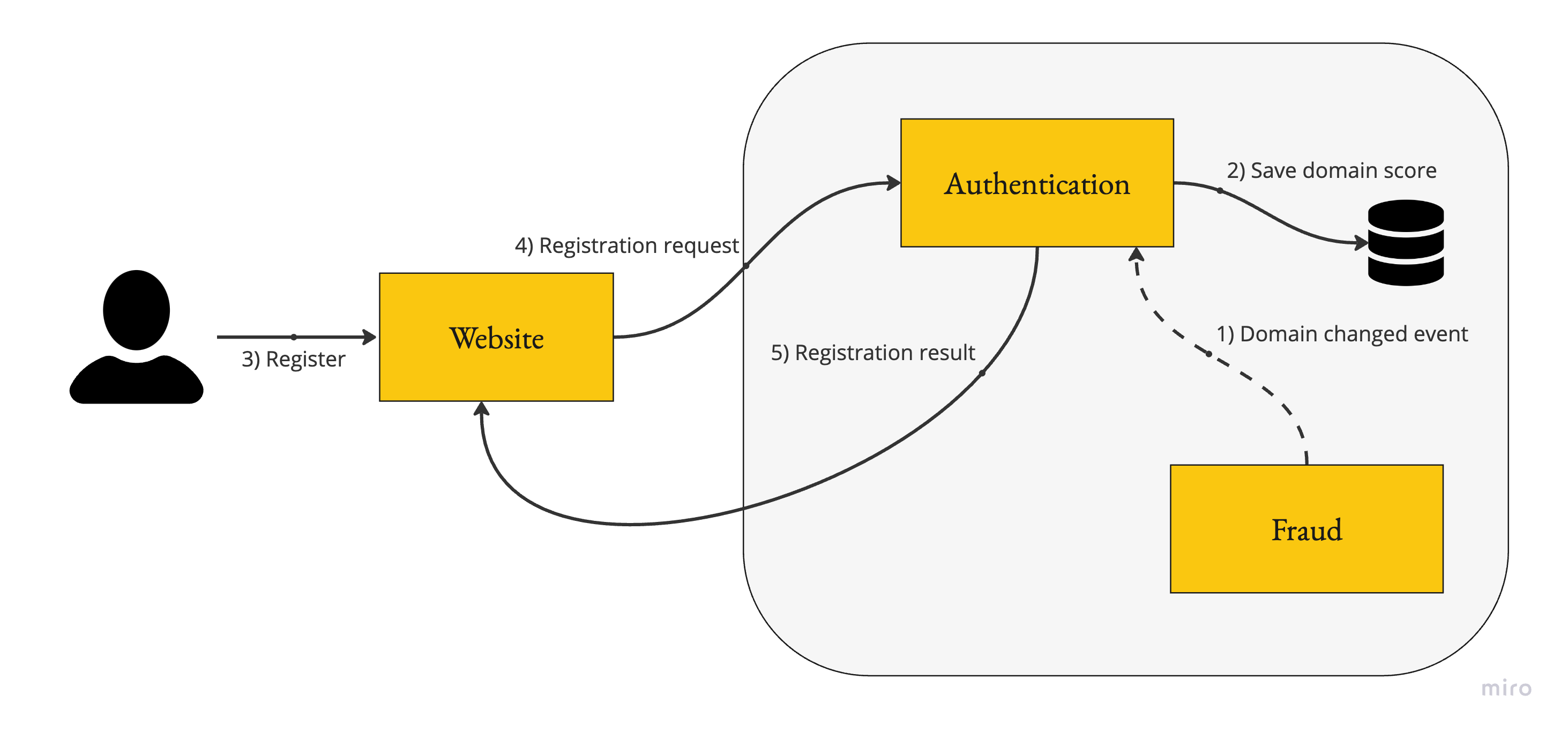
The Authentication service saves a local copy of each domain’s fraud score based on events. The registration flow relies on this data, avoiding the online network call to the Fraud service. Here are the main pros and cons:
Pros
Resilient: This approach keeps the registration flow clean and resilient against errors in the Fraud service.
Faster: The team can avoid increasing the registration time by using a local copy and eliminating the network call.
Cons
More Resources: Saving a local copy and implementing an event-driven approach requires more time and resources.
Stale Data: In some cases, the registration may rely on local, outdated data that is not current with the Fraud service.
Which is Better?
As always with software, the answer is “It Depends.” In our case, keeping the registration flow error-free and fast is more important, and the risk of using stale data is acceptable.
However, other scenarios might not be worth it. For example, with a Reports service used monthly by top-tier customers expecting real-time data, fresh data is more valuable than avoiding errors and delays.
Real-Life Example
Our Product Manager assesses the tradeoff using an example from her own life. She manages the PRD project, which contains design status and artifacts. To keep it up-to-date, she has two options:
Online: Before publishing an update, check in with the designer and design software for the most recent version and status.
Offline: Receive automated updates when new versions and statuses are published.
It depends on the stage of the project. Early on, when updates are weekly, waiting a few hours for the designer is not an issue. The online process could work. Closer to launch, offline updates (with more effort to process them) are more effective when daily updates are needed.
Conclusion
Two of my friends have complementary mantras: one says, “Always Async” (favoring offline processes), and the other says, “It Depends.”
As a Product Manager, even with precise functional requirements, non-functional ones are critical for perfect execution and user experience. Understanding and discussing tradeoffs is an essential skill.
My approach is (almost) always to go with the offline process, considering it depends on the context.