
#55 - Domain-driven AI
Why AI Needs Domain-Driven Design to Overcome Language Barriers

Domain-specific LLM
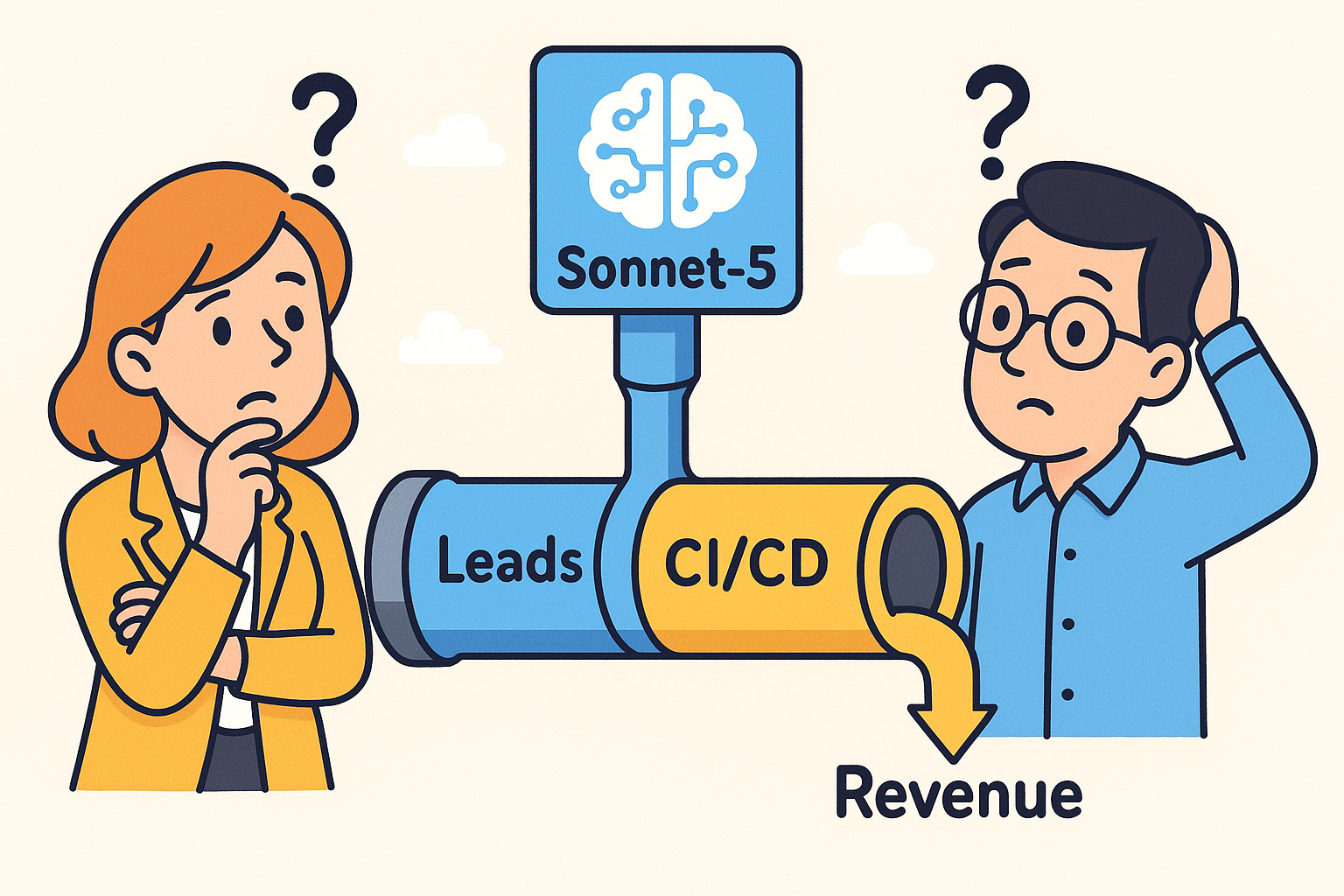
AI research companies will need to build large-language models (LLMs) tailored specifically to certain sectors, domains, and industries. This specialization will support high-quality AI agents and drive greater adoption. Soon, we might see models like O4-sales or Sonnet-5-devops. This isn’t a new idea; it’s rooted in the principles of domain-driven design.
It has been more than 20 years since the term domain-driven design was coined, yet I still find it relevant today. To be clear, I read the entire book (as challenging as it was).
One persistent trend is the difficulty we face with language and communication within organizations. That’s precisely where bounded contexts and a ubiquitous language can help.
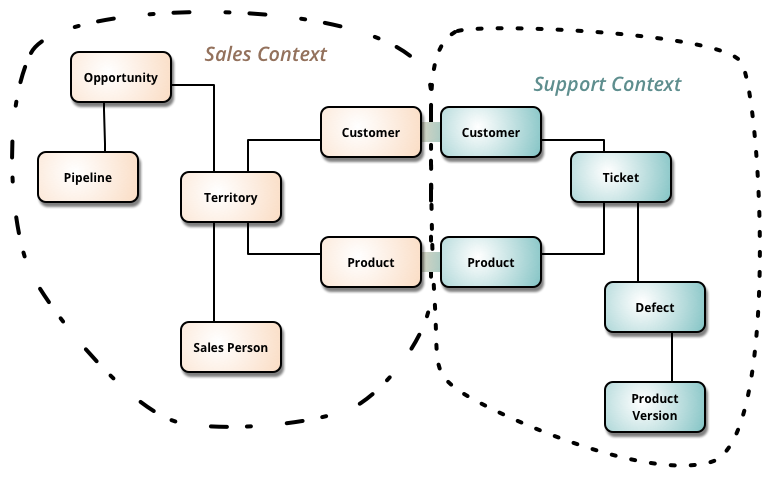
In the era of AI, these concepts are more relevant than ever. I believe they form a critical part of context engineering. We’ve already learned that good AI output depends heavily on good input. Input, in this sense, includes training data, instructions, additional documents, memory, and more. Yet language, the central component in LLMs, varies significantly between individuals and carries nuances that AI must bridge effectively.
Same word, different meaning
Let’s consider two examples
First example - Dan from Marketing
Dan, a marketing manager, uses GPT daily. One of his goals is to optimize his sales pipeline and automate as much as possible while remaining in the driver’s seat. He uses prompts like:
“How can I improve my pipeline?”
“Do we have any new leads today?”
Second example - Jane from R&D
Jane, a senior engineer, uses Claude daily. Her priority is to ensure infrastructure stability, prevent downtime, and maintain fast-paced task execution. She uses prompts like:
“Why is my pipeline taking so long?”
“Do we have new leads on what happened?”
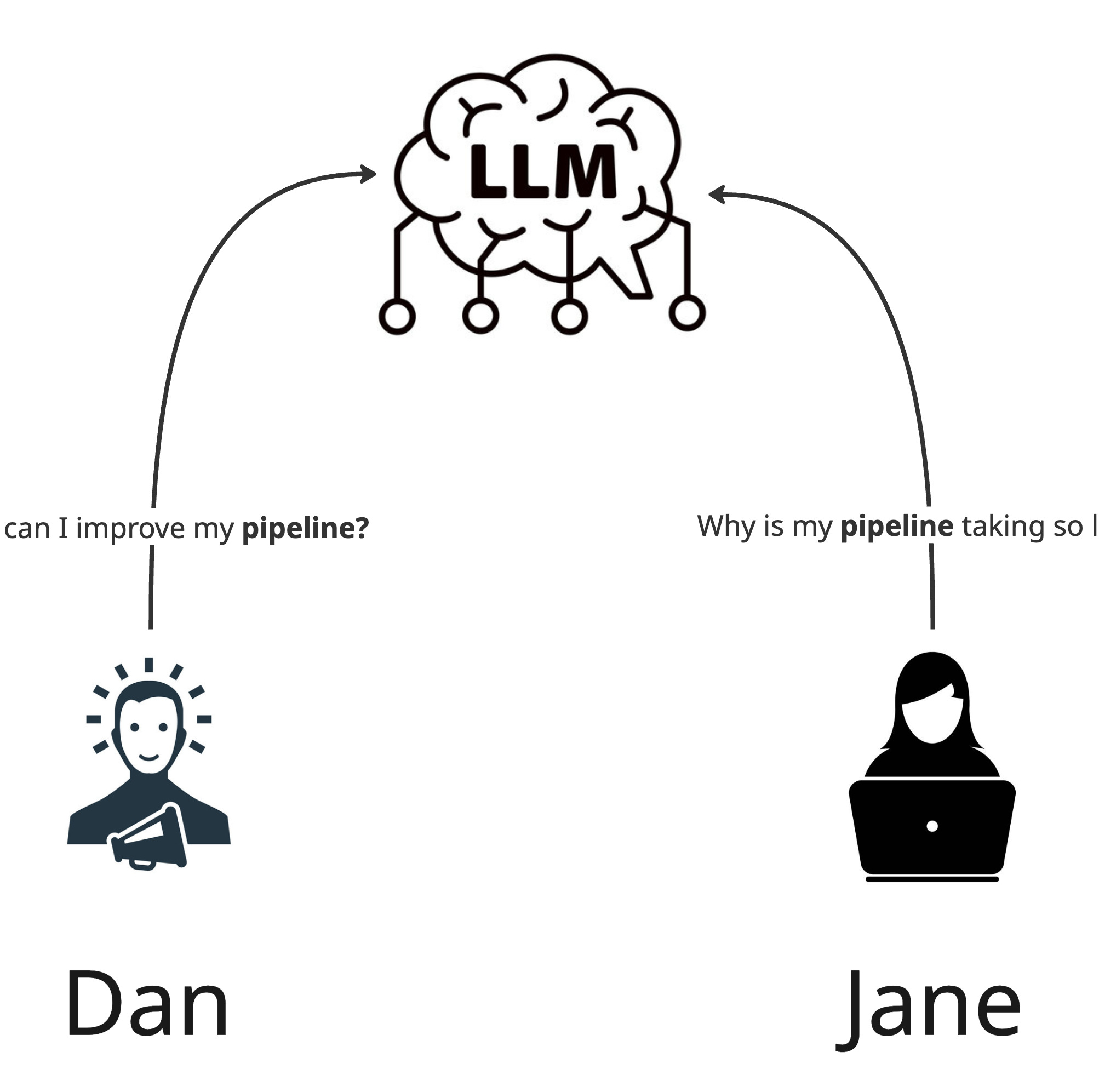
Both Dan (the marketing manager) and Jane (the senior engineer) use terms like “pipeline” and “lead.” Although LLMs are trained to recognize context, effective context engineering means minimizing the chance of misunderstandings by providing high-quality input. Therefore, a clearer prompt might look like:
You are a marketing expert, and your goal is to help me improve my lead pipeline. I work as an SDR at Acme Inc. Our leads mainly come from LinkedIn and visits to our website.
I’m a senior engineer at Acme Inc. Help me improve my infrastructure pipeline to optimize velocity. Be highly technical and creative in your solutions.
Without these clarifications, Dan might unintentionally receive a response about deployment pipelines and CI/CD automation, causing confusion and prompting him to clarify further or switch models.
The language barrier
Communication remains challenging with AI. This issue is amplified when autonomous AI agents encounter similar misunderstandings and must determine the correct context to reach accurate decisions. As AI agents increasingly operate across diverse domains, dedicated LLMs for these specific contexts will become necessary.
The solution to communication barriers lies in creating a shared language. This is where the concept of ubiquitous language comes into play. For example, an O3-sales model will understand terms like pipeline, lead, and QBR, while a Sonnet-5-devops model will excel in the CI/CD and Kubernetes ecosystems.
Organizations will face the challenge of clearly identifying their bounded contexts, selecting the models that best match their language, and bridging communication gaps between different departments (and their agents) using “translators.” For instance, when a marketing agent discusses a “pipeline” with a DevOps agent, the system will explicitly clarify what “pipeline” means within each domain.

Summary
The next evolution in communication will focus on improving shared language and terminology between humans and AI applications, and among AI agents themselves. Achieving this will depend heavily on dedicated, domain-aware, industry-specific LLMs.