
#56 - My AI agent required more engineering than prompts
A case study on automating release changelogs and the messy work of building production-ready AI.


Intro
My team and I used to create monthly changelogs for product releases. The manual process took about a week, with over a day just to gather the necessary information. I built an AI agent in n8n that streamlined this process to be real-time, reducing the time it takes to just a couple of hours.
In this post, I’ll dive into the details of how I did it and why it’s not as easy as LinkedIn makes it sound. When I hear someone say, “AI should be able to do that, right?” I recommend they try it out and see for themselves. The TL;DR is that it was much harder than you would expect.
Let’s dive in.
High-Level Architecture
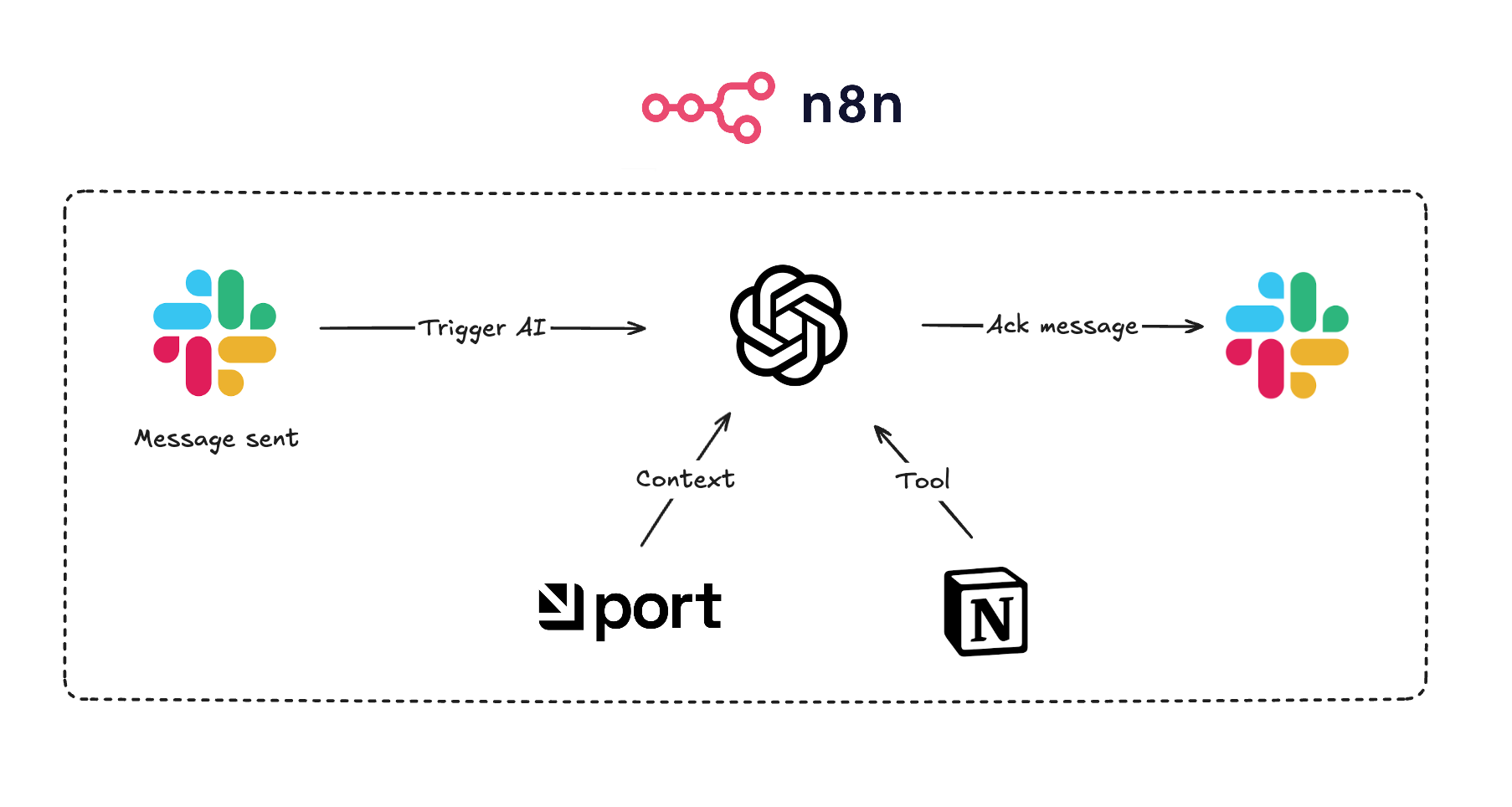
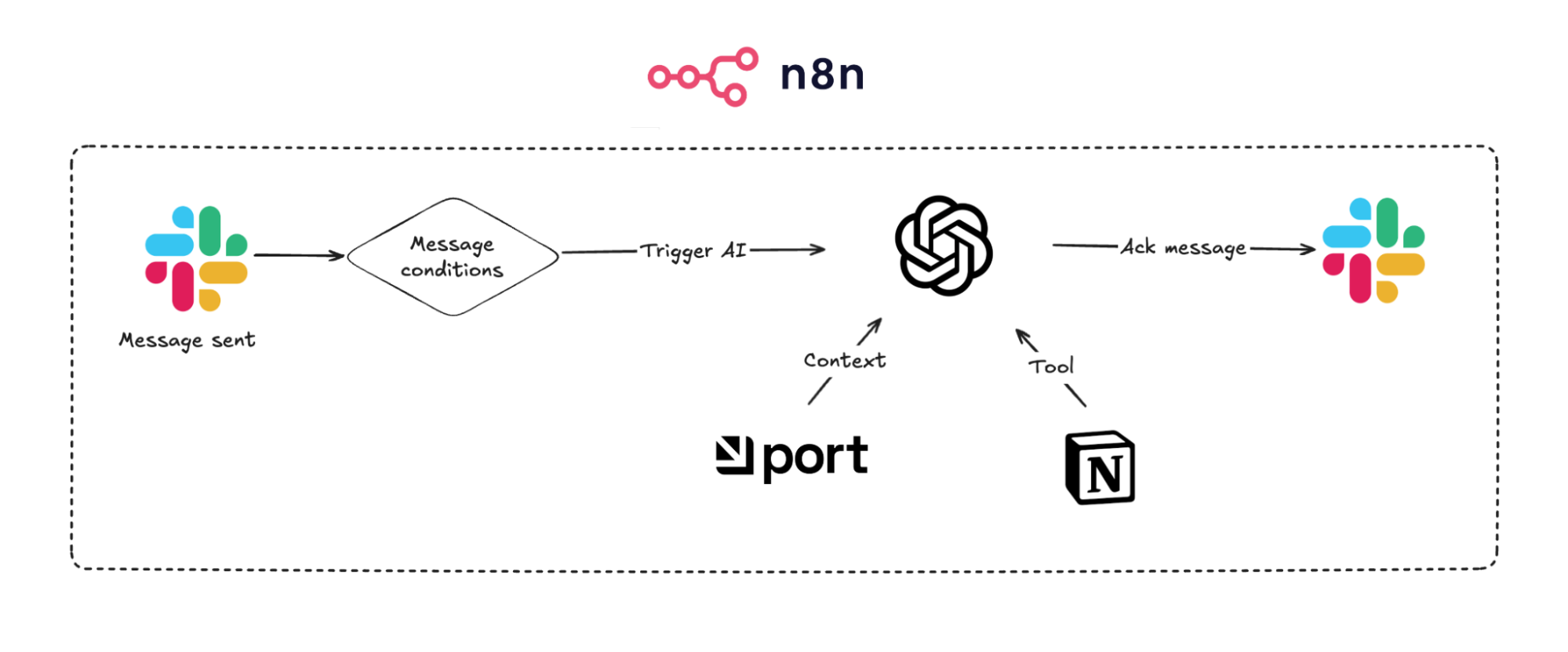
The business workflow is such that every new feature release is announced internally on our Slack. Instead of gathering everything at the end of the month, the agent picks it up in real-time and notifies in the thread once it’s finished.
The workflow starts with a Slack trigger, then moves to a simple agent with access to broader context in Port (our internal developer portal, which is the product we’re building) and Notion, the tool where the release changelog is written.
The context in Port includes product themes, the owner PM, and some additional context on the release itself. The Notion page is essentially a running list of the month's releases.
To hint at the next steps, here’s how the current flow looks in n8n:
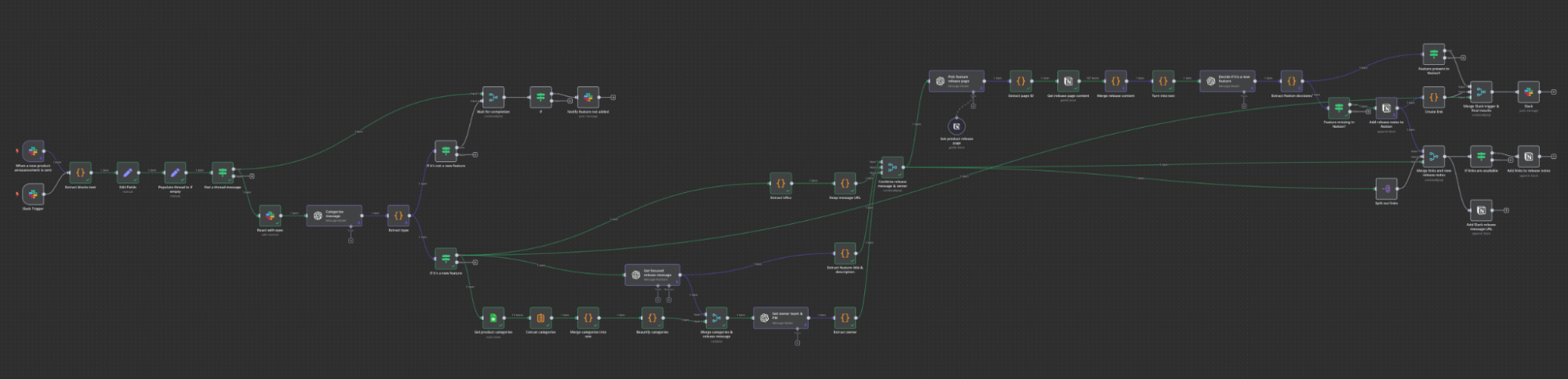
When I’m asked, “How much time did it take to build it?” my answer is, “Probably two to three hours, but that initial time investment grew as I discovered more edge cases and worked to improve its accuracy.”
Similar to my post on building the MCP, building is one thing, but getting it to work is completely different.
Let’s go into the different parts and tradeoffs I encountered along the way.
The Slack Trigger
For the first take, I assumed the AI agent would do most of the heavy lifting in analyzing the message. But then I got this release note:
Pete has joined the channel! 🚀
Happy to announce that Pete is now part of this channel. With this new addition, expect sharper insights, faster feedback loops, and an extra boost of energy—drop a welcome message below!
Confusingly, the workflow was getting triggered when new members joined the Slack channel. The AI model didn't figure out this wasn't a feature release and added it to the monthly changelog. A funny mistake, but an unacceptable one.
At this point, I was faced with a tradeoff that would surface again: invest more time in deterministic logic, or prompt and hope for the best with non-deterministic LLMs.
My solution was to improve the workflow:
I saw the trigger step had a
typeand an optionalsubTypeproperty.I added an
IFsection so that for achannel_joinevent, the workflow wouldn’t trigger.
Like with all development tasks, getting it to work took its toll:
Replicating the case with the right trigger (using execution logs and the debug editor).
Testing each step separately to ensure it worked as expected.
Testing E2E to see if the flow was broken.
I found a few more cases like this (such as message deletions), and I handled them all in a similar way.
Infinite Automation Loop
While still in the experimental phase, I got a message saying I was DDOSing our Slack. A single release note got 50+ replies from the agent in less than a minute.
Here, I learned an interesting fact: sending a message in a thread is also considered a channel message. This created a loop:
Similar to the previous case, I added a step that filters out thread messages. At this point, the workflow looks somewhat like this:
The AI Part(s)
At this point, you might be missing some context on what I actually expected the AI agent to achieve. As it turns out, it was too much to ask from a single prompt, which led me to another tradeoff: one agent with massive instructions versus multiple smaller, more focused agents.
Similar to the previous tradeoffs, and perhaps generally in software, one large function is easier to build but harder to maintain and test, so I went with the focused agents approach.
Here is a list of the agents in the process and the task each had:
Type of release - This agent needs to categorize the release into pre-defined buckets based on instructions and historical assignments. The type of release later helps determine whether we need to add it to the changelog.
Ownership - This agent gathers product component ownership from Port, categorizes the release message into one of these components, and determines ownership (which is later important for follow-ups on the changelog to add visuals, etc.).
Message guidelines - This marketing-oriented agent knows our language, previous releases, and changelogs, and determines how to condense a detailed Slack announcement into a one-liner for our changelog.
Release page - While it may sound easy, figuring out the right release page in Notion for the month is not a trivial task (I will elaborate on that below). This agent should output the page ID for the rest of the process.
Existing or new announcement - In some cases, we build the release page in advance or send a couple of variations of the same feature in Slack. This agent needs to determine whether the release page already contains this feature.
I believe it's clearer why going with smaller, more focused agents was the right choice in this case, but it also made our workflow much more complicated in terms of different failure points and data flow. I won’t draw it out, but you can imagine how it gets closer to the first workflow screenshot showing the final n8n flow.
I won’t dig into each step, but I do want to cover a few interesting steps and findings I had.
Ownership AI
This AI agent is relatively simple and started like this:
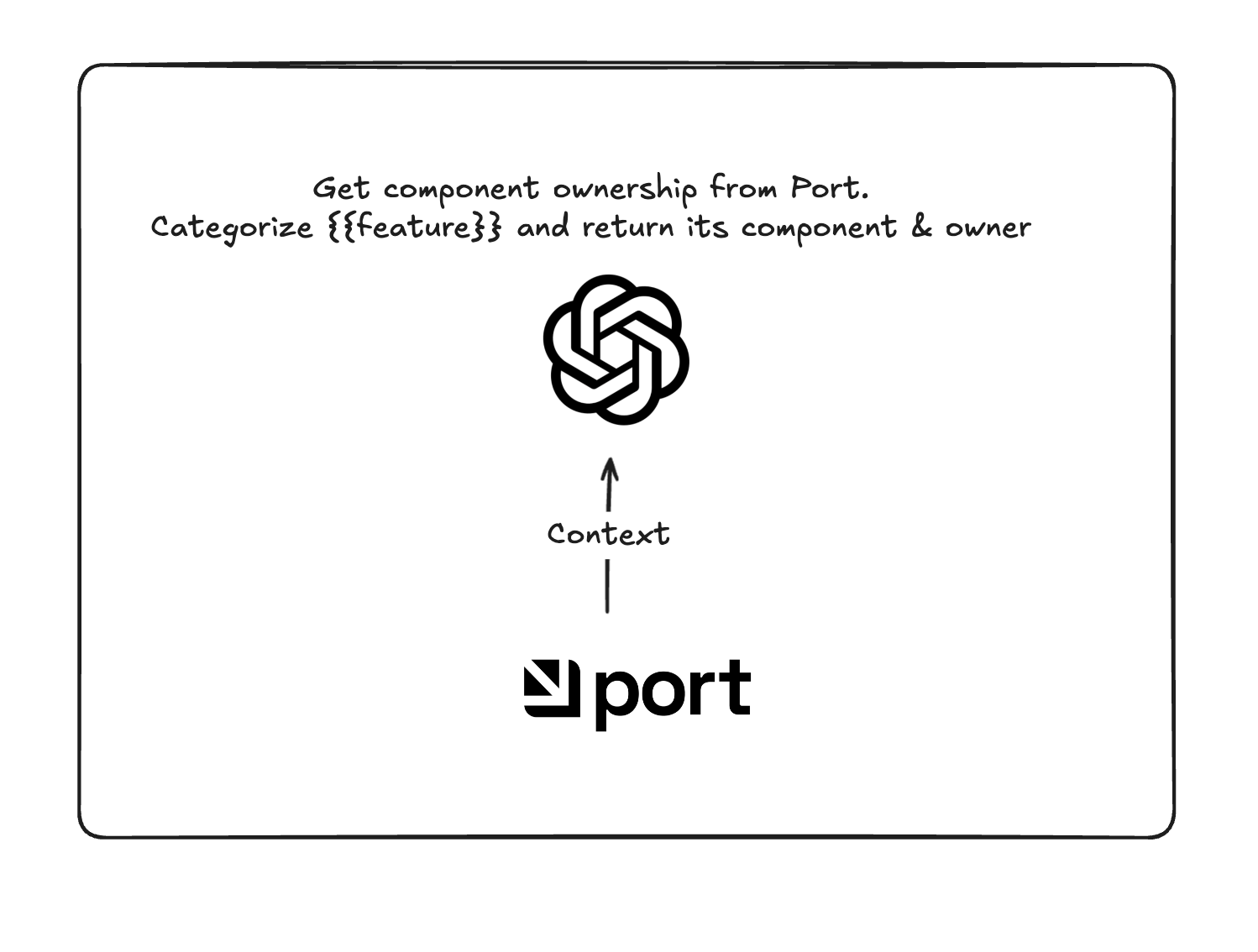
However, the results were not great. I played with different models, but I felt it was something that GPT4.1-mini should be able to do (and thus save cost and time).
After some research and testing, I was able to improve it by adjusting the tool itself, rather than the prompt or the model.
Before the change, it was an array of JSON objects:
[
{
“Name”: “frontend”,
“Owner”: “Matan”
},
{
“Name”: “backend”,
“Owner”: “Phil”
}
]After the change, it was a long formatted string:
##Frontend\nOwner:Matan\n##Backend\nOwner:Phil\nIt seems like the string version worked much better.
Release Page & Existing Announcements
This was the trickiest part and really the heart of the workflow. If you just add everything being sent your way to incorrect pages, it misses the point and creates a burden rather than value.
At first, I had one agent tasked with both finding the relevant page and deciding whether the announcement should be added to it:
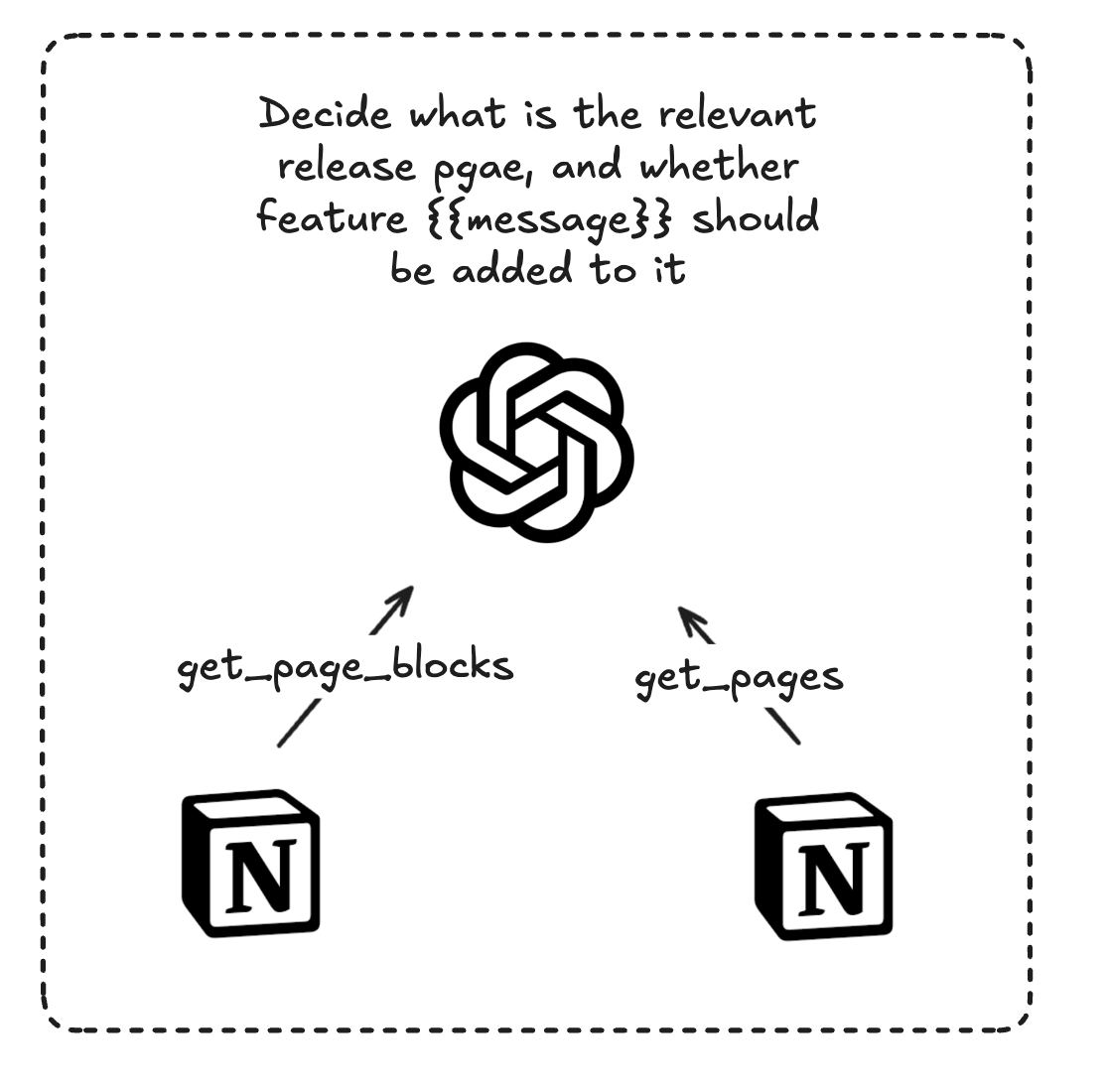
The get_pages tool had a search function in Notion with a predefined query (e.g., “release notes - {{month}}”). The agent was able to run it with the right parameters, but I noticed that for some reason, Notion search didn't return the right page or the right order.
For example, a search for “Release notes - July 2025” brought up “Competition - July” as the first result. I tried increasing the number of results (from 10 to 50), but it was both inaccurate and consumed way too many tokens (as the response is a very long, non-LLM-optimized JSON).
After a few days, I had a better idea. I made sure all the release notes pages in Notion were under one parent page (it was a page, not a database) and changed the tool to bring that page's content instead. This way, I ensured the right pages were somewhere in the response. It didn’t solve the token consumption, but at least it worked.
At this point, I still saw many duplications in the release page, suggesting the agent was deciding to add announcements that were already on the page. I looked at past executions and the agent debug logs and saw that the tools did return the right data. You would expect the AI agent to “figure that out.”
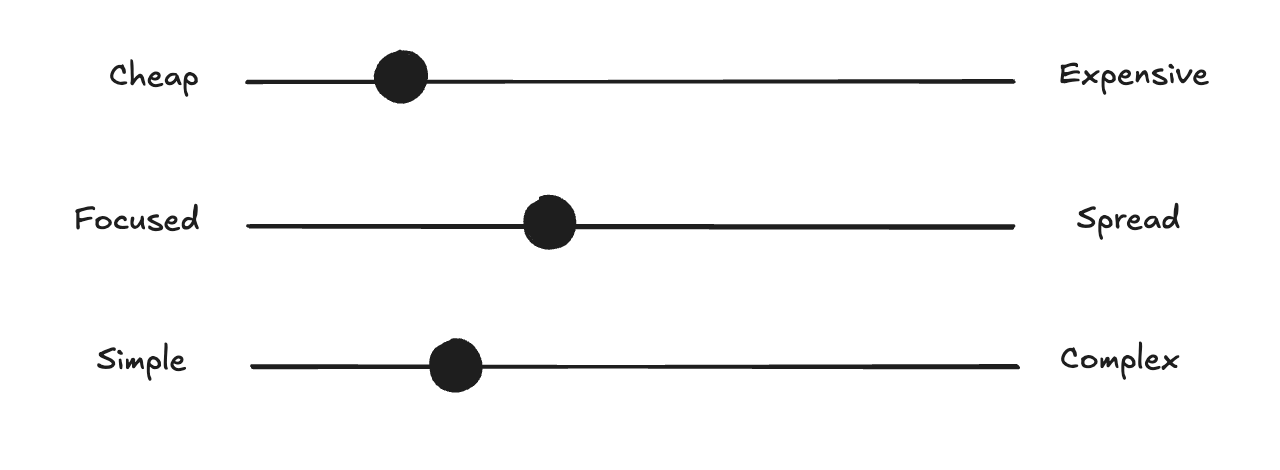
I want to pause for a second and return to the tradeoffs I mentioned. The ideal implementation of an AI agent would be cheap, with broad context that requires minimal intervention, and capable of doing a very complex task.

The reality is, you need to compromise and make tradeoffs to get the agent to actually work and provide good results consistently.
I was able to eventually get better results by applying these steps:
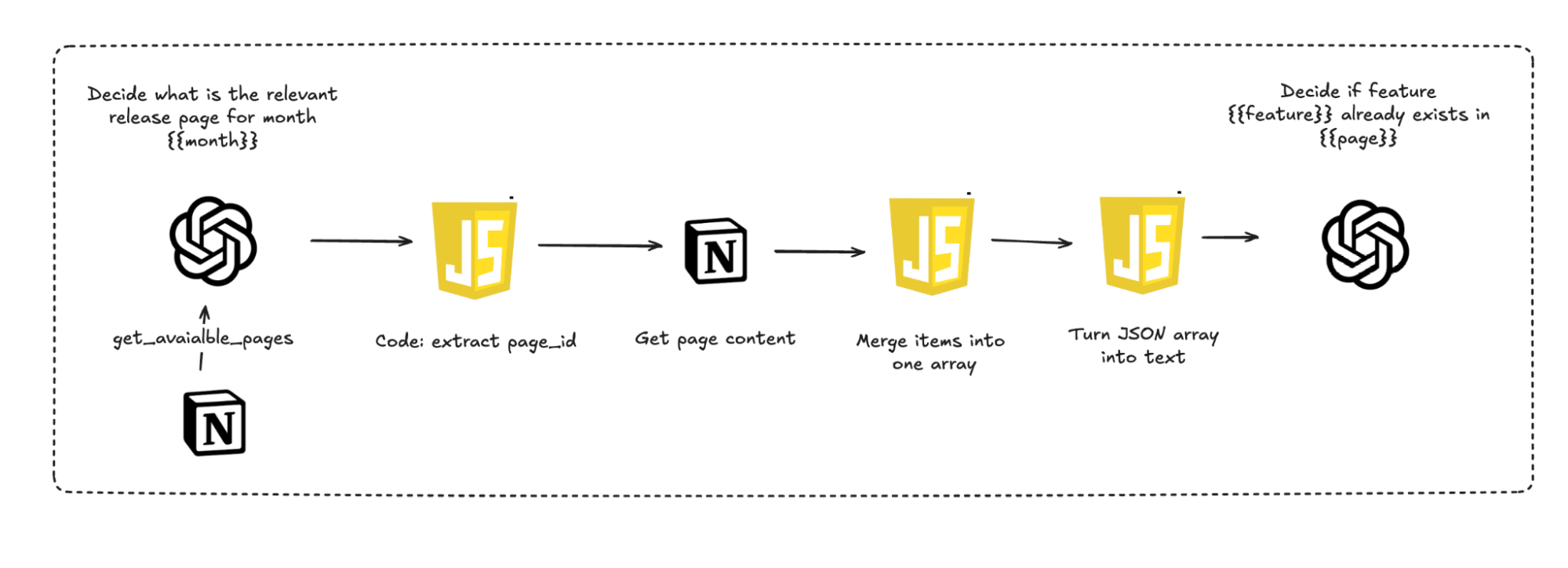
Now, some of you might raise a good point: Is this still an AI agent? The final step is just an LLM. That’s true, and I believe the definition of AI workflows and agents isn't binary; you make tradeoffs along the way. If an engineer decides to use a third-party library or an external automation tool instead of writing code, is he still an engineer? Of course, he is. Similarly, the entire flow is agentic and involves the right context, tools, and memory to achieve the task.
Conclusions
Building AI agents is definitely fun and satisfying, but it’s also challenging. Getting them to work in production and provide consistent results is hard. I highly recommend everyone try different frameworks and start today.
Here are my main learnings along the way:
Start small - While LinkedIn makes it sound like AI agents are ultra-smart AGIs, reality is different.
Test, test, test - Make sure you have the right framework to test and debug the agent in different scenarios.
Anticipate changes - The agent will change a lot after you first deploy it, so make sure you have the attention to monitor it and think about unique edge cases you wouldn’t expect.
You don’t always need a hammer - Sometimes, a simple 4.1-mini LLM step can do the trick. Don’t force the use of thinking models and complex tooling if the task can be achieved with simpler tools.